Bootloaders - UBOOT
- Victor Hanna

- Jan 17, 2023
- 4 min read
Updated: Dec 10, 2025

In this blog post we will be describing what a bootloader is and where it fits into the boot process. This is an extremely valuable skill to possess as a security researcher of embedded/IoT systems. We will be describing:
The Bootloader
The Bootloaders' Role
The three phases of the boot process
Passing control to the kernel
What a device tree is
The Bootloader
The bootloader allows a system to successfully load the underlying operating system kernel of an embedded/IoT system. Bootloaders are "generic" in their overall execution so as to allow for the diversity in underlying kernels and hardware types. A bootloader can be seen as a arbiter of flow control between initial power-on of a device and the execution of kernel running in memory.
The Bootloaders' Role
The bootloader has two main functions:
Initialization of the System
Loading of the Kernel
Just after power-on or reset an embedded system is seen to be in an absolute minimal functional state. Many of the controllers and supporting chip sets are not yet online in this initial state. In this state, there is a requirement to anticipate the systems functionality using the currently available resources of the system.
The initial functionality is handled by on-chip static memory (ROM), known as bootstrapping, which allows the embedded system to setup additional phases prior to the final operational state of the system.
The final operational state occurs when the kernel has finally been loaded into RAM and is executed. Once this state has been achieved the bootloader is no longer required and the memory that was previously allocated is reclaimed and reused by the system.
The 3 phases of the boot sequence
Phase 1: ROM Code
Due to the minimal supporting controllers and chipsets available at initial boot, for instance large enough flash memory to hold a large instruction set, the initial execution of instructions after a power-on or reset is typically stored on-chip on the SoC. This execution of instructions is known as ROM Code and is loaded onto the chip upon manufacturing.
The ROM Code loads the chunk of instructions onto a SRAM peripheral device. The predominate reason that SRAM is used is due to the lack of a need for separate memory controller for its functionality. This makes SRAM a great choice as it is not bound by a controller initialisation.
Some examples of an SRAM peripheral device used by ROM Code are:
NAND memory
Flash memory connected through SPI
MMC
It is typical that the boot sequence, as executed by the ROM Code, can "fallback" to a number of possible other sources, such as:
Ethernet
USB
UART
In some cases, the SRAM capacity is not large enough to support a full bootloader and in these cases, an SPL (Secondary Program Loader) is used. This SPL itself is loaded into SRAM and at the very end of the ROM Code phase, the SPL is found at the start of SRAM and continues on where the ROM Code left off.
Phase 2: SPL (Secondary Program Loader)
The main job of the Secondary Program Loader is the loading of an additional TPL (Tertiary Program Loader), which is loaded into DRAM. Upon load into DRAM the TPL then follows on from where the SPL left off, but most significant execution flow is now executed within Dynamic Memory.
Phase 3: TPL (Tertiary Program Loader)
The TPL typically takes the form of a fully-fledged bootloader, such as U-Boot, which allows for an interactive prompt. This interactive prompt allows for user input in order to run various commands, some of which are:
The loading of new boot images into flash storage
Execution of memory and storage management tasks
Once this phase has been completed the kernel is typically located in memory and execution is then passed to it via the bootloader.
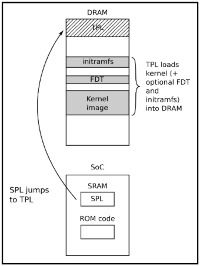
Figure 1. Mastering Embedded Linux Programming – Second Edition (Chris Simmons)
Passing control to the kernel
Prior to progressing to full kernel control the bootloader is required to offload details by providing plain information to the kernel so that the kernel can execute cleanly. The following information is passed to the kernel by the bootloader:
The type of SoC used
The size and location of RAM and CPU speed
The Kernel Command Line
The location and size of the DTB (Device Tree Binary), this is optional and is dependent on whether the device support DTB
The location and size of the initial RAM disk (initramfs), this is also optional and is dependent on whether the File System itself will be offered up as an initial RAM disk or not
This information in most modern ARM architectures is typically passed to the kernel using a Device Tree.
Device Trees
A device tree is merely a structured attempt at describing an underlying computer system, such that, a Linux kernel can gain insight into the under-the-hood components of the system that it is running on.
As its namesake implies the details that are described the system are structured in a tree-like fashion, with the root of the tree (Root Node), denoted as a slash ‘/’. All subsequent nodes in the tree are further denoted using a name, value property e.g. name = ‘value’

Figure 2. The above describes a simple node, which details the model of the selected board.
In order for the device tree to be usable by the bootloader and kernel, it must be presented to both the bootloader and the kernel as a binary file. The Device-Tree-Compiler (DTC) is used to compile a .dts source into a .dtb binary for presentation to both of the interfaces.



Comments